App Discovery with Google Play 阅读笔记
这个是 Google Search Blog 中的一个文章,正好10.1假期读到,这里简单做个阅读笔记。这个系列文章一共分为三个部分:
App Discovery with Google Play, Part 1: Understanding Topics
主要介绍了如何给apps 分到合适的主题上去。
App Discovery with Google Play, Part 2: Personalized Recommendations with Related Apps
主要介绍了如何进行 apps 的排序,以及如何实现个性化推荐。
App Discovery with Google Play, Part 3: Machine Learning to Fight Spam and Abuse at Scale
主要介绍了如何用机器学习的方法来探查和对抗作弊。
下面就这三部分读到的内容,简单做一个笔记。
Part1
App Search(类似 Google Play 中的或者 AppStore 中的)不但需要按照精确名字来查找,很多用户也需要按照 Topic 查找。即查找“horror games” 或者 “selfie apps” 等。
如何设计一个 ML 算法,可以自动将一个新出来的 app,划分为某个类型的游戏呢?
先来看看面临什么问题:
- app 量级大概几百万,topic 量级大概上千;(人工肯定是搞不过来的)
- 每天有万级别的新 app 上架(根据 part3的描述);(一个新游戏来了,往往用户行为的数据是空的(而且下载量这些,往往也对区分类型没啥帮助是不),所以一般要依靠对游戏名称,摘要(开发者上传游戏时候所写)等 meta 信息进行 embedding,形成特征并进行学习)
- 有些 topic 内容足够多,比如”social networking“,那么好学,而大多数长尾 topic,训练样本很少;(可能只有几款游戏?)
开始的时候他们用了 DNN 方法,学习到了一些关键字特征,但是非常容易的陷入了过拟合。即在训练集上很不错,但是到了测试集,泛化能力很差。
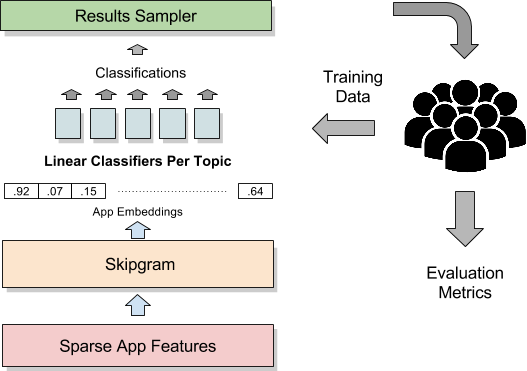
改进办法是用机器学习的 Skip-gram model训练了一个用来描述 apps 的语言模型。 (SGM是用一个 word 预测周围的 word) We trained a neural network to learn how language was used to describe apps. 注意,虽然也是用人类文字,但是在 apps 场景下,语言的使用习惯可能和其他场景(论坛、blog等)是不同的,所以作者这里的方法和描述都很准确。
学完了后,基本上每个词都得到了一个 Embedding。
因为语言模型的样本足够(其实是无监督的,只要语料足够多即可),所以一旦建立起语言模型,再从 embedding 到 topic 的工作就简单很多了。
但是这样做又遇到一个问题,就是分类器对于冷门游戏分类不好,他们built a separate classifier for each topic and tuned them in isolation,没太看懂怎么做的。
然后再想提高,就引入了人工标注的方式,让人来提升样本{app, topic}的质量。
Part2
光理解 topic 可能还不够,为了更好服务用户,如果能够根据每个用户的口味偏好给他推荐 apps 就更好了。
在”People Also Like “部分,推荐的是和他当前 app 互补的 apps,而非同 topic 的其他 apps。这个也好理解。
一个用户之前经常搜索和主动点击的行为,可以很大程度上表示他的真实兴趣。例如一个人之前主动找了很多的graphics-heavy games,很可能他更喜欢这种大型模拟类游戏。那么他在安装一个塞车游戏的时候,你推荐图像质量高的,肯定比那些简单图形骗小孩的要效果好很多。
怎么做的呢?经典的两步法:
- 召回(用协同过滤,下载了这个 app 的用户也下载了哪些 app);
- 个性化的re-rank;
召回过程是离线做的,因为需要大量的统计信息才能做 CF。他们实际上是做了一道 KNN。这里同样用到了 NN 来对 next install 进行建模学习,然后用 app 的 embedding 来做 NN search。
这个和我们的推荐系统很像,都是用 NN 方法来学习模式,并embedding实体(我们是 query 他们是 apps),然后再进行 recall和 rank。
具体到特征层面,召回的apps embeddings(相当于对相关性的一种 representation),再结合当前用户历史行为,以及当前用户的 context(地区,语言,搜索历史等),进行排序。
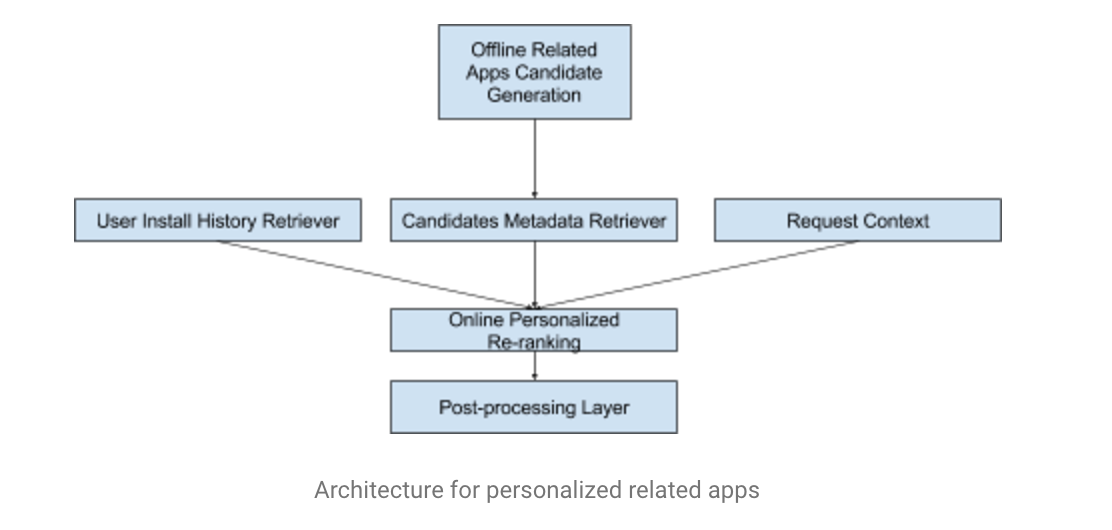
这里作者提到的是 online real-time training,但是没有展开来讲。
Part3
针对 apps 本身有害的检测
很多 bad actors,试图提交非法的,对用户有害的,违反Google 规定的 apps,当然不行了,所以机器学习在这里又派上了用场。
从几个方面入手来探测和组织这类 apps - 用概率网络来分析文本(类似垃圾邮件检测),用 Google Brain来探测图片(比如图片涉黄等),静态和动态的 APK 分析(比如一个号称免费的 app调用了验证指纹等高危的 api)。这些办法通常比人工审核更加有效。结合人类专家的辅助,基本上能保证在开发者提交的几个小时之内,就可以得到过还是打回的反馈。
打击刷 apps 排名的行为
apps 本身过了审核,但是 bad eggs 可能会通过刷评论和刷点击下载的方式来提高这个 apps 的排名。因为你的反作弊算法一上线,可能作弊者的套路也会快速变化,故这里不太适用之前的”静态“机器学习方式了。他们引入无监督的方式生成样本,同时结合有监督的方式进行学习来解决这个问题。听起来还是很新颖的。
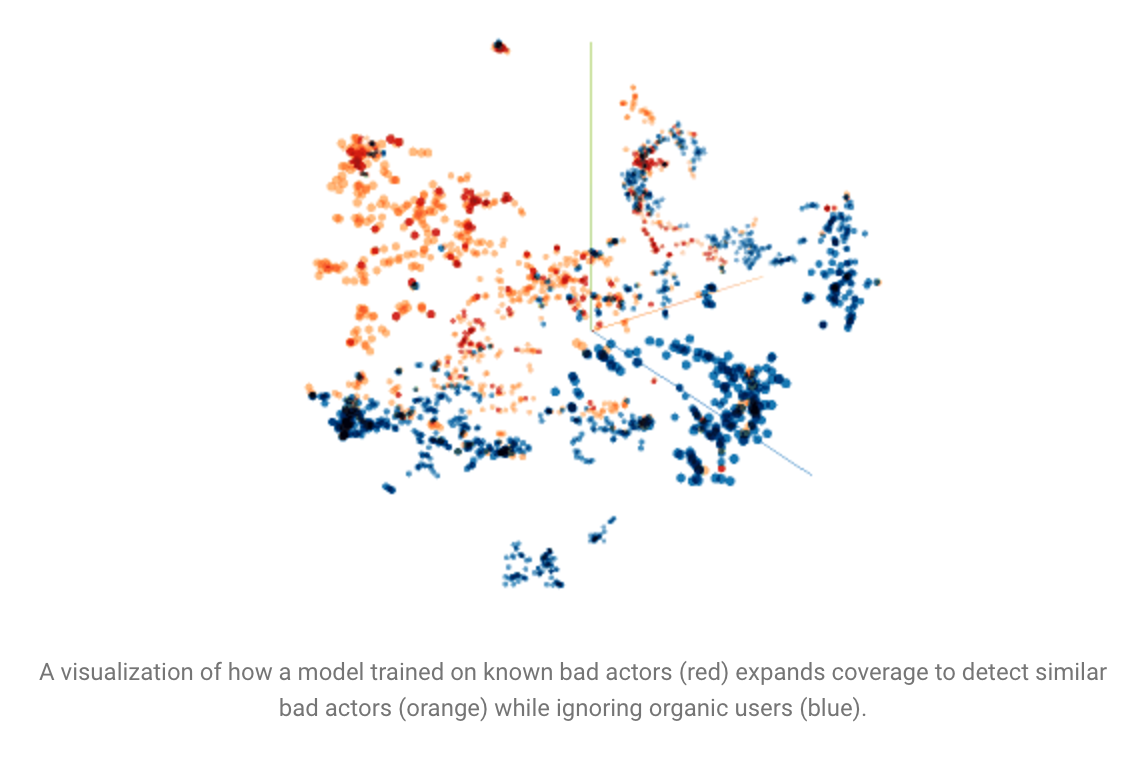
利用细分维度的行为,可以探测出可疑程序。比如如果一个程序的行为(engagement)绝大多数只来自一个数据中心,而Organic 的行为是按照一个健康比例分布在多个数据中心的。 利用这些被发现的 apps,就能早到行为的发送者,即一部分bad actors,再训练一个模型找到其他相似的 bad actors。不过这也不叫无监督学习啊,不还是用人找特征先么…
总结一下,以上3个 parts 都是从比较宏观的角度介绍 Google Play 是如何应用机器学习来解决业务问题的。大体上是比较主流的思路,在ranking 这块,online-retrain 是亮点,反作弊这块,无监督对抗是亮点。不过遗憾的是这两块文章都没有展开来讲。